
The Agentic Brand: The Architecture Behind AI-First Brand Consistency

October 17, 2025
How to encode brand as code and scale content quality without human bottlenecks
The Problem Statement
A Chief AI Officer recently mentioned building a "style coach agent" - an AI system that would automatically ensure every piece of content matches the company's brand voice. When I asked him to elaborate, he described the exact technical challenge that most AI-first companies are trying to solve: how do you encode brand as code?
This looks like a marketing problem disguised as a technical one. Yet this is AI architecture pur sang. When we can encode what it is what we do, then we’re able to move fast.
Here's why, and what the right approach looks like. This is exactly what I have spent all my free time in in the past year and a half.
Why This Matters
(The Business Context)
AI-first companies face a unique brand challenge:
- Content volume is exploding (10x more than traditional companies)
- Creation is scaling (not just marketing - everyone creates)
- Speed is competitive advantage (no manual back-and-forths)
- Quality cannot degrade (brand is your moat)
The technical challenge becomes: How do you build a system that:
- Understands brand voice as rules, not just examples
- Enforces those rules in real-time during content generation
- Adapts to different contexts (sales vs. technical vs. marketing)
- Integrates with any AI model (tool-agnostic)
- Learns and improves over time
- Scales infinitely without degradation
Why Generic LLMs Fail:
- ChatGPT (or any LLM) doesn't know your brand or company (every prompt starts from zero)
- They forget context between sessions
- Generic fine-tuning is expensive and inflexible
- Prompt engineering doesn't scale (requires expertise every time - your staff are not great prompters (yet))
- No systematic way to enforce rules
The Solution: Agentic Brand Management
An AI system that acts as a persistent layer between your team and any LLM, ensuring brand consistency automatically.
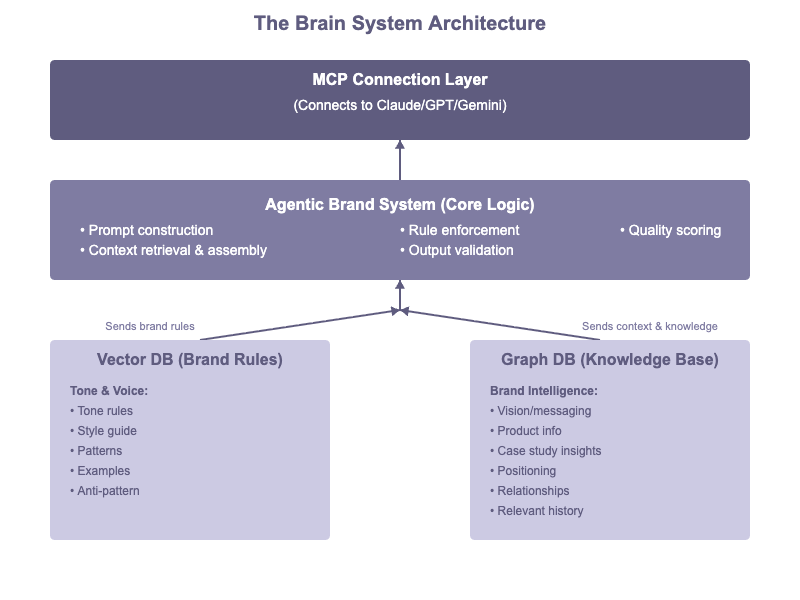
The Technical Architecture
Core Components:
1. Vector Database (Brand Rules as Embeddings)
Purpose: Store tone of voice instructions and enable semantic similarity matching
Technology: Pinecone, Weaviate, Qdrant, or similar
What Goes Here:
- Writing style guidelines (we have a proprietary method for that)
- Terminology preferences ("say 'platform' not 'tool'"- white lists and black lists)
- Tone descriptors (we have a propriotaty method for that)
- Anti-patterns ("never use jargon like 'synergy'")
- Context-specific rules (technical vs. marketing tone
- Templates for how we do things - types of output - from investor update, to annual report, to blogs and LinkedIn posts. (we have encoded many different types of output into templates)
- Guidelines for different situations with best practise and our own rules of thumb - ready for LLM application and supported decision making: e.g. issue management, brand management in M&A situations.
Why Vector DB:
Traditional keyword search fails for style rules because style is contextual. Vector embeddings capture semantic meaning, allowing the system to understand "this feels off-brand" even without exact matches.
Example:
Query: "How should we describe our product?"
Vector search retrieves:
- "Use concrete language, not abstract concepts"
- "Focus on customer outcomes, not features"
- "Active voice preferred: 'You can' not 'It is possible to'"
The system finds *semantically similar* rules even if the exact words don't match.
2. Graph Database (Knowledge Relationships)
Purpose: Store unstructured company knowledge and connect concepts
Technology: Neo4j, TigerGraph, Amazon Neptune, or similar
What Goes Here:
- Product documentation and specifications
- Customer stories and use cases
- Internal terminology and definitions
- Historical decisions and rationale
- Market positioning and competitive context
- Organizational knowledge (who, what, when, why)
Why Graph DB:
Brand consistency is part tone and largely knowledge. When someone writes about "our approach to X," the system needs to know what that approach actually is, how it connects to other concepts, and what we've said about it before.
Example Graph Structure:
(Product: “ServiceNow Integration” for example)
-[SERVES]-> (Industry: Financial Services)
-[DIFFERENTIATES_BY]-> (Feature: Real-time sync)
-[COMPETES_WITH]-> (Competitor: Workato)
-[USED_IN]-> (Case Study: ING Bank)
-[MENTIONED_IN]-> (Blog Post: "Why Banks Choose...")
When you query about “ServiceNow for financial services”, the graph traverses these relationships to provide complete context.
3. MCP Connection Layer (Tool-Agnostic Integration)
Purpose: Model Context Protocol for standardized AI model communication
Why MCP Matters:
AI models evolve rapidly. Building directly on one model's API means rebuilding when you switch models. MCP provides an abstraction layer - your brand system works with whatever "AI head" you choose.
Benefits:
- Switch from Claude to GPT to Gemini without rebuilding - portable system
- Test multiple language models simultaneously
- Future-proof against model changes, new players
- No vendor lock-in, your Brain is yours where-ever you want to use it
- Standard protocol as industry converges
Architecture:
Your Application
↓
MCP Client
↓
MCP S
↓
[Vector DB] + [Graph DB]
↓
MCP Connection
↓
AI Model (Claude/GPT/Gemini/Future Models)
4. LLM-Guided Processing (Intelligence Layer)
Purpose: Use current LLMs to process and organize incoming content
How It Works:
When you add a document to the system:
- LLM reads it and extracts key information
- Categorizes content type (instruction vs. context vs. fact vs. opinion)
- Determines storage location (vector for rules, graph for knowledge and the rules are connected to the graph as well)
- Creates semantic embeddings for vector search
- Identifies relationships for graph connections
- Updates knowledge structure automatically
Example Processing Flow:
Input: "We always position ourselves as the integration experts, not generalists. This differentiates us from competitors who try to be everything to everyone."
LLM Analysis:
- Type: Instruction (positioning rule)
- Storage: Vector database - connected to one or more nodes in the graph
- Embedding: Creates semantic vector for "positioning strategy"
- Graph: Creates relationship: (Company) -[POSITIONS_AS]-> (Integration Experts)
- Anti-pattern: Adds to "Don't position as generalist" rules
```Why LLM-Guided:
- Humans are bad at structuring data consistently
- LLMs excel at extraction and categorization and consistency
- Low-touch maintenance (system self-organizes)
- Continuously improves as you add content
How It Works (The User Experience)
Scenario 1: Sales Proposal Generation
User (Salesperson):
"Create a proposal for Rabobank, a financial services company looking to modernize their workflow set up. Focus on our integration capabilities and emphasize security."
What Happens Behind the Scenes:
- MCP layer receives request, forwards to style coach agent
- Agent queries vector DB: Retrieves tone of voice rules for "proposals" and "financial services"
- Agent queries graph DB:
- ServiceNow knowledge and capabilities
- Financial services industry context
- Integration positioning and differentiators
- Security messaging and compliance
- Rabobank information (if available)
- Agent constructs enriched prompt with all context + brand rules:
System: You are writing a proposal in the name of company X.
Brand voice rules:- Professional but approachable tone
- Use concrete outcomes, not abstract features
- Active voice preferred
- Focus on "you can" not "we offer"
- Target: Rabobank (financial services, Netherlands)
- Topic: Workflow modernization
- Key differentiator: Real-time integration capabilities
- Security: Emphasize compliance (GDPR, PSD2, ISO27001)
- Proof: Similar work with ING Bank (reference available)
- Sends to LLM (Claude/GPT/whatever) via MCP
- LLM generates proposal using provided context and following brand rules
- Agent validates output against brand rules (quality check)
- Returns to user: Proposal that sounds like Company X, contains accurate information, emphasizes right points
Time: 3 minutes
User's Perspective:
"I asked for a proposal and got something that sounds exactly like us, with correct information about our Workflow capabilities, properly positioned for financial services, with relevant security messaging - in 3 minutes."
Scenario 2: Blog Post Creation
User (Technical Leader):
"Write a blog post about our approach to AI-powered automation in enterprise environments. Make it technical but accessible. Target audience: CTOs at mid-market companies."
What Happens:
- Agent retrieves tone rules for "blog posts" and "technical content"
- Agent retrieves all knowledge about "AI-powered automation" from graph:
- Technical approach and architecture
- Enterprise requirements we address
- Customer examples and use cases
- Competitive differentiation
- Industry trends and context
- Agent identifies related concepts:
- Integration capabilities (connects to automation)
- Workflow expertise (our platform for automation)
- Case studies in enterprise environments
- Enriched prompt sent to LLM includes:
- Brand voice for technical blog posts
- Complete knowledge about AI automation
- Target audience considerations (CTO-level)
- "Technical but accessible" balance guidelines
- Output validated against technical accuracy and brand voice
- Returns 800-word blog post
User's Perspective:
"I described what I wanted and got a publishable draft that sounds like me, accurately represents our AI automation approach, is pitched at the right technical level for CTOs, and includes relevant examples - in 2 minutes."
Scenario 3: Brand Consistency Analysis
User (Marketing Manager):
"Analyze this web page copy against our brand guidelines and suggest improvements."
What Happens:
- Agent receives existing content
- Queries vector DB for all applicable brand rules
- Analyzes content against each rule:
- Tone alignment
- Terminology consistency
- Voice patterns (active vs. passive)
- Message positioning
- Structural preferences
- Identifies violations and strengths
- Returns detailed analysis:
Brand Alignment Score: 67%
Strengths:
✓ Professional tone maintained throughout
✓ Correct terminology usage ("platform" not "tool")
✓ Good use of customer outcomes
Issues Found:
✗ Too much passive voice (23% of sentences)
Example: "Solutions are provided by our team"
Better: "Our team provides solutions"
Best: “You get solutions”
✗ Generic positioning language
Example: "We offer comprehensive solutions"
Better: "We integrate your systems in real-time"
✗ Missing key differentiator
Content doesn't mention integration expertise
Suggested Rewrite:
[Provides improved version following all brand rules]
User's Perspective:
"The system caught brand inconsistencies I didn't notice and provided specific fixes. It's like having a brand guardian with built in copywriter reviewing everything."
The Implementation Details
Data Architecture Diagram:
Processing Flow (Step-by-Step):
- Input Phase
- User describes what they want to create
- System identifies intent and context
- Determines content type (proposal, blog, email, etc.)
- Query Phase
- Vector search: Find relevant brand rules
- Content type rules (how to write proposals)
- Audience rules (how to address CTOs vs. developers)
- Context rules (technical vs. marketing tone)
- Graph traversal: Find relevant knowledge
- Topic information (what we know about X)
- Related concepts (what connects to X)
- Supporting evidence (examples, case studies, data)
- Enrichment Phase
- Combine brand rules + knowledge into comprehensive context
- Structure prompt with:
- System instructions (who you are)
- Brand rules (how to sound)
- Knowledge context (what to say)
- User request (what to create)
- Constraints (word count, format, audience)
- Generation Phase
- Send enriched prompt to LLM via MCP
- LLM creates content following all provided context
- Receives generated output
- Validation Phase
- Check output against brand rules
- Verify factual accuracy against knowledge graph
- Score consistency (0-100%)
- Identify any violations or improvements
- Refinement Phase (if needed)
- If score below threshold, agent adjusts prompt
- Regenerates with corrections
- Repeats until quality threshold met
- Output Phase
- Return validated content to user
- Include quality score and any notes
- Optionally provide "why" explanations for choices made
Key Technical Decisions Explained:
Why Two Databases Instead of One?
Vector Database:
- Optimized for semantic similarity search
- Fast retrieval of "rules like this one"
- Handles fuzzy matching (similar concepts)
- Perfect for: style guidelines, tone rules, patterns
Graph Database:
- Optimized for relationship traversal
- Answers "what connects to what"
- Handles complex multi-hop queries
- Perfect for: knowledge, context, history
Different data types require different optimal storage. Combining both gives best performance.
Why MCP Instead of Direct API Calls?
Portability:
- Works with any AI model that supports MCP
- No lock-in
- Easy to switch or test multiple models
Future-Proofing:
- New models integrate automatically
- Protocol updates benefit entire ecosystem
- Industry standard emerging
Flexibility:
- Can route different requests to different models
- Can use multiple models simultaneously
- Can implement fallback strategies
Example:
if (content_type === "technical"):
use Claude (best at reasoning)
elif (content_type === "creative"):
use GPT-4 (best at creativity)
elif (requires_speed):
use Gemini Flash (fastest)
Why LLM-Guided Processing Instead of Manual?
Scalability:
- Humans can't structure thousands of documents consistently
- LLMs process at scale without fatigue
Maintenance:
- System self-organizes as you add content
- No manual tagging or categorization required
Intelligence:
- LLMs understand context and relationships
- Extract implicit information humans might miss
Example:
Document: "We won the ING Bank deal because of our real-time integration capabilities, which their previous vendor couldn't match."
Human categorization:
- File: Case studies
- Tag: ING Bank
LLM extraction:
- Entity: ING Bank (financial services, Netherlands)
- Differentiator: Real-time integration
- Competitive Context: Competitor lacked this capability
- Success Factor: Speed of integration
- Relationship: (ING) -[CHOSE_US_FOR]-> (Real-time integration)
- Relationship: (Real-time integration) -[BEATS]-> (Competitor)
%20(2).jpg)
.png)


